
 Table of Contents Watch What I Do
Table of Contents Watch What I Do
Three such tasks are illustrated in Figures 1-3. They all involve reformatting textual databases: an address list, a set of match scores, and a bibliography. Each can be accomplished using an editor with a macro definition capability, but this requires careful advance planning and is difficult to get right the first time. Moreover, any programming solution suffers from excessive rigidity--in reality, the tasks are defined incrementally and may be extended as more examples are encountered. In practice, people are likely to accomplish such tasks by manually editing each entry, perhaps using global search-and-replace to perform sub-tasks where feasible.
Programming by demonstration seems a natural way to approach these problems. Rather than programming a task, users need only demonstrate examples of how to perform it, from which a program is synthesized that performs the task itself. [Nix 84] has investigated the application of "by example" techniques to text editing by looking only at inputs and outputs, and seeking a transformation that maps blocks of input text into corresponding output blocks. While this works well for rigidly-structured tasks like that of Figure 2 (which was taken from Nix's thesis), it breaks down when faced with less artificial transformations that involve rules and exceptions, like those of Figures 1 and 3. In contrast, the scheme developed in the present paper adopts a procedural stance: editing actions are recorded and generalized into a program that transforms input into output. This seems to offer better potential for complex, ill-structured, editing problems where many different cases may arise.
Figure 2. Reformatting a simple database
Cardinals 5, Pirates 2.
Tigers 3, Red Sox 1.
Red Sox 12, Orioles 4.
Yankees 7, Mets 3.
Dodgers 6, Tigers 4.
Brewers 9, Braves 3.
Phillies 2, Reds 1. [[arrowdbldown]] GameScore[winner 'Cardinals'; loser 'Pirates'; scores [5,2]].
GameScore[winner 'Tigers'; loser 'Red Sox'; scores [3,1]].
GameScore[winner 'Red Sox'; loser 'Orioles'; scores [12,4]].
GameScore[winner 'Yankees'; loser 'Mets'; scores [7,3]].
GameScore[winner 'Dodgers'; loser 'Tigers'; scores [7,3]].
GameScore[winner 'Brewers'; loser 'Braves'; scores [9,3]].
GameScore[winner 'Phillies'; loser 'Reds'; scores [2,1]].
To automate this task in a conventional manner one would build a parser for names and addresses. The parser would need to know, for example, that Calgary is a city; that postcodes and phone numbers have a certain definite format; that quadrants of the city can be N.W., S.W., ..., and are meant to form part of the street address; and so on. But new information and exceptions appear constantly.
Figure 3. Reformatting a bibliography
%A Abi-Ezzi, S.S.In the second example, for instance, we find that a suite number should be given a line to itself (and an apartment number, in example 7). We find that Banff, although it will appear in the list of cities, can also be part of a street name. Examples 5 and 6 give a new twist to the format for telephone numbers. Example 6 contains an error in the person's family name which will not create any difficulty but warns ominously of problems that may arise if more crucial parts of the examples were misspelled or mistyped.
%D * * * %T A 1986
%T An implementer's framework for knowledge view of PHIGS
%J Computer elicita
%J Proc First Graphics and European Conference on
%O Application
%P 12-23
%O September
%K *
%A Allen, February
%K *
%A Ackley, J.F.
%A Koomen, J.A.
%D D.H.
%A Hinton, G.E.
%A 1986
%T Planning using a Sejnowski, T.J.
%D 1985
%T temporal world m
%J A learning algorithm for Artificial Intelligence
%O Boltzman
%J Cognitive March
%K *
%A Allen, Science
%V 9
%P 147-169
%K J.F.
%D 1983
%T *
%A Addis, T.R.
%A Maintaining knowledge Hinton, G.E.
%D 1987 * about tempo
%J Comm ACM
%V * * 26
%P 832-843
%O May
%K * [[arrowdbldown]] Abi-Ezzi, S.S. (1986), "An implementer's view of PHIGS", Computer Graphics and Applications, pp. 12-23, February.
Ackley, D.H., Hinton, G.E. and Sejnowski, T.J., (1985), "A learning algorithm for Boltzmann machines", Cognitive Science, Vol. 9, pp. 147-169.
Addis, T.R. and Hinton, G.E. (1987), "A framework for knowledge elicitation", Proc First European Conference on Knowledge Acquisition, September.
Allen, J.F. and Koomen, J.A. (1986), "Planning using a temporal world model", Artificial Intelligence, March.
Allen, J.F. (1983), "Maintaining knowledge about temporal instances", Comm ACM, Vol. 26, pp. 832-843, May.
With TELS the job is undertaken very differently. The user begins editing, signaling to the system that she is doing so, and edits the first block in the natural way. She selects the place after "Bix,*" (the symbol "*" is used here to make the space character visible) and types RETURN. She selects the place after "N.W.,*" and types another, then after "Calgary,*". Finally she selects the phone number "284-4983" and types RETURN again to erase it and insert a separating blank line. Finally she signals to the system that the example is finished. Basically the user has typed RETURN after each comma, but the "N.W." is special and so is the phone number.
Now TELS takes over. It suggests selecting the place after "Bryce,*" and inserting RETURN, suggestions that are accepted by the user. (The user interface for displaying and accepting suggestions is simple and not particularly novel; this paper focuses on the programming by demonstration aspects instead.) The same happens after "Suite 1,*". The system then suggests inserting RETURN after "2741 Banff Blvd.,*", which is rejected by the user who relocates the cursor to follow "N.W.,*" and types RETURN. The rest of the example is predicted correctly, as are the next two examples. However, on the "Helen*Binnie" line, only the last seven digits of the telephone number "(405)220- 6578" are selected, and the user has to correct this. Trouble occurs again in the next line, where RETURN is suggested immediately before "S.E.,*" instead of after it; again the user makes a correction. The remainder of the task is executed correctly.
The text in this example is what we call "semi-structured": the user can recognize the addresses, phone numbers, and so on, but the system has no such concepts and can only interpret user actions in terms of units like letters, delimiters, and digits; and combinations of them like words, lines, and paragraphs. This contrasts with the approach of [Myers 91b] which begins with built-in knowledge of the document structure and relates editing actions to structural elements--in our example, elements like name, street address, and so on.
Our editing model supports the notion of current text position, which may be either a location or a piece of selected text, along with the following operations:
To recover the information lost by ignoring the details of individual move commands it is necessary to infer what information determines the target of a locate action. Because the user might have in mind any of several different location procedures (e.g. skipping a constant number of words or lines, locating the beginning of a word or paragraph, finding a certain left or right context), it is worth recording as much relevant information as possible. With each action, attributes are recorded that characterize the place at which it occurs. The attributes rely on a lexical decomposition of the text into units such as characters, words, lines and paragraphs. Of course, different applications may call for different lexical categories--we are not promoting our particular choice of attributes but rather the methods of generalization that are based on them.
Three basic kinds of attributes are used. The first characterizes the local context of the current position by specifying the preceding and following words. The second gives positional information relative to enclosing units of text, such as beginning, middle, or end of a file, paragraph, or line: we call these "lexical" attributes. Lexical attributes provide less local, and much less detailed, information than the local context. The third measures relative distance from the previous position, and can be expressed in units such as characters, words, lines, and paragraphs.
Identifying steps to merge Different steps of the trace are merged in order to form loops and increase the predictability of the action sequence. In general terms, the aim is to find the smallest procedure that accounts for the trace. However, there is a trade-off between the procedure's size and the accuracy with which it "accounts for" the trace. This trade-off can be expressed in terms of the entropy of the predictions [Witten 91], and the best procedure is one that optimizes the entropy. Unfortunately, to find it involves enumerating all procedures that account for the trace, and there is a huge number of these [Gaines 76].
Practical systems do not attempt to enumerate and evaluate all procedures. Instead they form "context" models that merge similar steps when they occur in sufficiently similar contexts [Witten 86]. Translated into the editing domain, these produce the rules of thumb:
We also restrict merging to eliminate overlapping loops but permit nested ones by adding the rule:
* do not merge steps if this creates a branch into an already-formed loop.
The first rule results from the fact that the procedure formed must be executable in order to provide any advantage to the user--underspecified actions such as insert-or-select will not help. However, actions with different parameters can be merged. For example, two select actions with different character strings--like "284-4983" and "229- 4567" on the first two lines of Figure 1--can be merged by finding a regular expression that covers them both, as described below. Also, insert actions that specify different text may be merged: although this will not produce an executable program step it may reflect unpredictability that is inherent in the task.
Just because the steps involve the same actions does not necessarily mean that they play the same role in the procedure. Merging steps indiscriminately, even though they match, can reduce predictability by losing the correct context within the procedure. The second rule highlights the importance of context, but does not provide a rationale for deciding how much context to use. Our present implementation does not take context into account, but allows the user to correct errors caused by overgeneralization.
Generalizing attributes and parameters Associated with locate actions are attributes that must be combined when steps are merged, as must the parameters of select actions. Many methods of generalizing data types have been identified in the machine learning literature. We need ways of generalizing lexical attributes (beginning, middle, or end of textual unit), numeric attributes (relative distances), and character strings (local contexts).
The first two are simple. Within each unit (file, paragraph, line, word) the "beginning" and "end" values are generalized to "extreme" while the "middle" value is generalized to "any". For example, beginning-of-line and end-of-line are generalized to extreme-of-line; if middle-of-line is present too then the position-within-line constraint is abandoned. Different absolute-position attributes are treated according to the word, line, paragraph, file hierarchy. For example, since beginning-of-line implies beginning-of-word, the latter is dropped if the former is present.
Numeric attributes affect the procedure only if they remain constant at every occurrence of a step. Executing a step on every third word, for example, causes the "word" measure to remain constant. More importantly, these attributes serve to restrict the region or "focus of attention" in which the system must search for a certain context. For example, if the number of words and lines skipped since the last editing action varies but the number of paragraphs remains constant at zero, attention is restricted to the current paragraph when seeking a new context in which to execute the current step. Also, the sign of these attributes dictates the direction of search when locating a new position.
Generalizing character strings Character strings, such as the parameters of select actions, are generalized into a string expression that covers the different examples. It is trivial to find a regular expression that satisfies a given set of examples, for it need be no more than a list of the examples. To further constrain the problem one might seek the smallest regular expression that satisfies the examples. This can be found by enumerating all expressions from the smallest up, but unfortunately this is computationally intractable.
Instead, TELS generalizes character strings using a heuristic that finds common subsequences. Individual characters are related by a class hierarchy with such categories as letter, digit, punctuation, lower-case, non-alphanumeric, and this relationship is extended to strings of consecutive characters from the same class. Then common subsequences are identified. For example, suppose the strings "Bix,*" and "N.W.,*" are to be combined. This occurs in the task of Figure 1, discussed in more detail below. First their common subsequence ",*" is identified. Then the pattern "[letter]*,*" is constructed from the common subsequence and the first string. The square bracket notation denotes a character from that class, other characters (comma and space) are interpreted literally, and "*" indicates repetition one or more times. However, this does not match the second string, so the pattern is generalized to "[character]*,*".
The heuristic method that combines textual attributes is biased towards discovering specific patterns that characterize common subsequences of the character classes present in the strings. For example, the longest common subsequence of "299-2299" and "222- 8888" is "2...22..." (where the ellipsis "..." stands for any string of characters), but the heuristic finds the pattern "2...-..." instead.
Although identifying mergeable steps provides only positive examples of character strings that are associated with the step, negative examples will come from executing the procedure on different blocks of text. Indeed, having formed a procedure from a trace, negative examples may be found by re-applying that procedure to the same trace and finding places where incorrect predictions are made because of over-generalization (although this is not in fact done in the present implementation). None of the above methods accommodate negative examples, except the enumeration technique for regular expressions. Our ad hoc solution is to store "negative examples" (or patterns generalized from several negative examples) with the pattern as they are encountered.
The problem of generalizing the context attribute is slightly different from that of generalizing the select parameter, for the extent of the context is not well-defined--it is not clear how far the preceding context should extend to the left, nor the succeeding context to the right. The simplest solution is to select a unit that constitutes the context, say a word. Unfortunately this eliminates the possibility of finding rules that depend on larger contexts. It would be better to carry contexts at several different lexical levels: word, line, sentence. Since different examples at each level will be amalgamated by the character-string generalization method, this would allow the discovery of any regularities that occur, regardless of their level. However, it is not done in the present system.
A step that specifies an insert action may or may not specify the text that is to be inserted. For example, if we were inserting phone numbers into an address list like that of Figure 1, the system would obviously not be able to predict the actual numbers. If we were inserting area codes, however, and they were all the same, then the system would be able to suggest them. In the former case, the user is simply invited to type the text. In the latter, the suggested insertion is presented for approval. If it is not approved, the system has to decide whether to generalize the program step into an insert action with unspecified text, or create an alternative step with the new text parameter and link it in to the program. This is the same decision as whether to merge two trace steps together when constructing the procedure from the trace, and is treated in the same way. If the user indicates that an insert action is inappropriate, the system asks for the correct action and amends the procedure accordingly using the same method as for initial procedure construction.
Other actions that are not accommodated in our present system, like delete, cut and paste, could be executed in the same way, by informing the user of the proposed action, awaiting confirmation, and soliciting the correct action in the case of an error.
Cases where the action involves finding a position in the text are more complex. The text is scanned from the current position until the attributes are matched. The direction of scan is indicated by the sign of the relative-distance attributes. The scan extends forward to the end (or backward to the start) of the smallest text unit (word, line, or paragraph) that contained all previous executions of this step (i.e. whose relative-distance count was zero). The match pattern is given by the context specifications associated with the program step, and the parameter in the case of a select action. The lexical attributes of the position (beginning, middle, or end of a unit of text such as file, paragraph, or line, etc.) which have remained constant in previous executions are respected in the scan.
If a position is found that satisfies these constraints, the user is informed of the proposed location and action. If the action is correct but the position is incorrect, the correct location is requested and the attributes associated with the program text are updated. If the action is incorrect, the correct one is solicited and the program amended.
When updating a program step to accommodate a new location in which it should be executed, there are two cases. If the correct position was overlooked by the scanning procedure, the program step is too specialized and must be generalized so that it would find the correct position next time. This involves generalizing the context attributes (or the parameter, in the case of a select action) to subsume the new positive example. However, if the scan finds a position that precedes the one indicated by the user (as occurs when editing the second line of Figure 1 and RETURN is suggested before "N.W.,*" instead of after it), the program step is too general and must be altered to avoid finding the incorrect position in future. This involves specializing the context attributes (or the parameter, in the case of a select action) to inhibit matching the new position, effectively treating the incorrect position as a negative example. It may also be necessary to generalize these attributes to ensure that the correct position is indeed matched, if it is not already.
Suppose now that the scan does not succeed in finding a position that satisfies the constraints represented by the attribute values. Rather than reporting to the user that the program step cannot be executed, a match can be sought with a generalized version of the attributes. This can be done in three ways. The extent of the scan can be increased, the lexical attributes can be over-ruled, or the context patterns can be generalized. It is not clear how best to balance these three possibilities. In any case, if weakening the attribute constraints does allow the scan to find a position for the program step, the system suggests the action as before, and if it is accepted, generalizes the attributes to subsume the new position just as it would if the user had suggested it.
In summary, whenever executing a program step involves finding a position in the text, the attributes associated with that step are used to constrain the position. Two kinds of bug may occur. Overgeneralization bugs cause the procedure to match a step with a place which should not have been matched. Overspecialization bugs cause it to miss places that should have been matched. Both cases are handled by generalizing or specializing the attributes of the program step accordingly.
A third kind of bug, incorrect program structure, occurs when a predicted action is actually incorrect (in contrast to the correct action being predicted at an incorrect location). Procedure execution is suspended and the user demonstrates the correct action, or sequence of actions, manually. The system will then merge the new trace fragment in with the existing program.
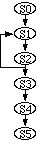
The program-creation mechanism generalizes the trace of Figure 4 into the procedure of Figure 5. The user is not involved in this generalization process: it takes place entirely behind the scenes. Nodes are considered to be mergeable whenever their actions (and parameters, where appropriate) are identical. For example, T1, T3, and T5 are mergeable, as are T2, T4 and T6. Whenever nodes are merged, loops are formed. However, mergeable nodes are only actually merged providing this does not create a branch into the body of an already-formed loop. For example, step T8 of the trace in Figure 4 is not merged with state S2 of Figure 5 even though they have the same action, since that would involve branching into a loop.
For locate actions, the attributes need to be generalized. An example of generalization is shown in Figure 6. The sequence generalizer determines that trace elements T1, T3, and T5 should be merged, and combines their attributes into those for state S1 of the program in Figure 5. This specifies that a "click" action occurs between "[character]*,*" and "[alphabetic]*", on the same line as the current position (because "distance" in "lines" is 0), and at the beginning of a word. ("[character]*" and "[alphabetic]*" are abbreviated "[c]*" and "[a]*" in the figures.)
Action Attributes ....... context ...... .......
distance ..... ......... position ..........
before after chars words lines word line
para file
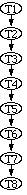 click Bix,* 2416 +10 +2 0 beg mid mid
mid
click Bix,* 2416 +10 +2 0 beg mid mid
mid
type return
click N.W.,* Calgary +19
+4 0 beg mid mid mid
type return
click
Calgary,* T2M +9 +1 0 beg mid mid
mid
type return
select `284-4983'
type return
Figure
4. Trace for first block of address list task Once a program has been created from the trace of actions on the first block of text, it is executed on subsequent blocks, with the assistance of the user where necessary. (In fact, it might have been better to undo the modifications and re-execute the procedure on the first block of text as well, both to provide an initial round of debugging and to show the user what has--and what has not--been learned. In the present example the procedure would fail on the first block in exactly the same way as it does on the second.)
Consider applying the program of Figure 5 to the second block (in this case, line) of Figure 1. State S1 finds the first comma (after the name) and S2 suggests a RETURN character, which is accepted by the user. A position satisfying S1 (after "Suite*1,*") is found before one satisfying S3, and so S2 suggests another RETURN , also accepted. Now S1 finds the comma after "Banff*Blvd." and suggests RETURN here. That is not what the user intended. She rejects the prediction and is invited to position the cursor correctly.
This is an example of an overgeneralization bug. The prior context "Blvd.,*" and the posterior context "N.W.,*" are recorded as negative examples with state S1 of the program. These will prevent S1 from matching a position with either of these contexts in future. Also, the context of the correct position indicated by the user is merged with that specified in the state, using the previously-described string generalization procedure, to ensure that the correct position will indeed be chosen in the future. In this case the position's prior and posterior contexts are "N.W.,*" and "Calgary,*" which already match the patterns "[character]*, *" and "[character]*" respectively that are stored with the state. (The current system is blind to other negative examples that may occur prior to the target position specified by the user. Again, it may be better to undo and re-execute the program step to identify bugs early.)
Figure 5. Program created from the trace
Action Attributes ....... context ...... .......
distance ..... ......... position ..........
before after chars words lines word line
para file
 start
start
click [c]*,* [a]* 0 beg
mid mid mid
type return
select
`284-4983'
type return
stop
The
program continues by predicting correctly the RETURN character following
"Calgary,*". This leaves it in state S2. Now it fails to identify a
position for either of S2's successors, states S1 and S3. Because the pattern
in S3, "284-4983", is specific, it is temporarily generalized up one
level of the character-class hierarchy, to
"[digit]*[op][digit]*", and a match is sought
again. This does indeed find the "229-
4567"
at the end of the second line of the task, and so the program predicts that
this item will be selected. (If a match had not been found, the pattern
"[digit]*[op][digit]*" would have been
generalized further, to "[alphanumeric]*[non-alphanumeric]
[alphanumeric]*", and so on.) When the user accepts this
prediction, the select action of state S3 is generalized to
"2[digit]*-4[digit]*" to accommodate the two
patterns it has actually been applied to.
Figure 6. Generalizing trace elements T1, T3, and T5 into program
step S1
Action Attributes ....... context ...... .......
distance ..... ......... position ..........
before after chars words lines word line
para file
T1
T2 click Bix,* 2416 +10 +2 0 beg mid mid
T3 mid
click N.W.,* Calgary +19 +4 0 beg mid
mid mid
click Calgary,* T2M +9 +1 0 beg
mid mid mid
[[arrowdbldown]]
S1 click [c]*,* [a]* 0 beg mid mid
mid
On
the third and subsequent blocks of text up to the fifth, the system predicts
all actions correctly. However, on the "Helen*Binnie" line, where the
telephone number "(405)220-6578" has a different format, it selects
just "220-6578" and predicts a cut action. The user rejects this
action and selects the whole string "(405)220-6578". Then the string
generalization algorithm is re-invoked to generalize the pattern, which was
previously "2[digit]*-[digit]*", to
"[character]*2[digit]*-[digit]*".On the sixth block, RETURN is predicted immediately prior to "S.E.,*", because only "N.W.,*" is stored as a negative example. When the user rejects this prediction and indicates the correct position for the click action, the system generalizes the negative example pattern to match "S.E.,*" too.
On the address-list task (Figure 1), manual execution of the procedure on the first block resulted in a trace of 8 steps (Figure 4), which was used to form a 6-node procedure (Figure 5). Execution of this procedure on the second block resulted in 10 editing actions, 9 of which corresponded to predictions accepted by the user. A position selection and corresponding action are both presented together to the user in a single dialog box. Consequently the 9 predictions actually corresponded to only 5 dialog boxes being generated, and accepted. There were a total of three points at which the user had to reject the system's prediction and substitute her own: they were described individually above.
The second task was included since it has been studied by Nix [Nix 84] as an illustration of his editing-by-example system. The trace was immediately generalized into the correct program.
Table 1. Performance of the system on three example tasks
Block
num Actions
Predicti Uses of
Nodes in
ber performe ons
acce debugger
procedu
d pted re
Address- 1 8
10
8
8
9
8
8
7
1
0
0
1 6
6
6
6
list (trace)
2
8
8
8
7
8
1
0 6
6
6
task
3
4
5
6
(Figure the rest
1)
Game-sco 1 11
11
11
0 13
13
re task (trace)
t
(Figure he rest
2)
Referenc 1 20
26
22
18
20
2
3
2
0 20
28
28
e-list (trace)
2
20 0
28
task
3
the
(Figure rest
3)
The
reference-list task (Figure 3) is more complex. The second block differs
from the first in that three authors are included instead of one, a volume
number is present, and there is no month. The third block has two authors but
no volume or page numbers. The final two blocks do not introduce any new cases.
Nevertheless, despite this degree of variation, the great majority of
predictions made by the system turned out to be correct.The effort in performing the three tasks, measured in both keystrokes and mouse-clicks, was compared with and without the programming by demonstration system. In the task of Figure 1 only one-third as many mouse-clicks, and one-third as many keystrokes, were required using the system. Figure 2's task produced even greater savings because without the learning system the fixed characters "GameScore[*winner*'" and ";*loser*'" were typed over and over again (although real users would likely be more resourceful). Figure 3 required slightly over half as many mouse-clicks and keystrokes because the debugger had to be used to instruct the system to form branches and supply inputs. Of course, these figures depend heavily on the number of blocks that are edited, but they give some idea of the savings for tasks of this size.
One might well question whether evaluation based on keystrokes and mouse-clicks provides a useful measure of the assistance given to the user by a programming by demonstration system. The real issue, perhaps, is the amount of thought that users must put into their actions, as much as the mechanical difficulty of actually carrying out those actions. To assess this, one could use an entropy-based metric that determined the information content of the user's decisions [Witten 91]. However, this too is open to debate: issues such as the perceived consequences of making an error (which will be strongly affected by the availability of a satisfactory undo function) and the relationship of failed predictions to the user's conception of difficult points in the task will probably outweigh statistically-based arguments in practice.
A true evaluation of a programming by demonstration system can only be achieved through controlled user studies. Unfortunately, our pilot implementation is not robust enough to support proper human factors tests of the efficacy of the procedural approach to semi-structured text editing with actual users. Moreover, testing systems which involve any kind of adaptation or learning is a major undertaking, as we have found from our experience of testing the METAMOUSE system for graphical programming by demonstration [Maulsby 91] and the PREDICT system for keyboard acceleration [Darragh 92]. Nevertheless, this is clearly an important area for future research.
The procedural approach adopted here, in which a trace of user actions is generalized into a program, offers significant advantages over a pattern-match-and-replace scheme such as Nix's [Nix 84] that operates on input and output only. The disadvantage -- that traces are confusing because users have many ways of doing the same thing -- is alleviated by (a) using a simple, abstract model of editing instead of raw low-level commands, and (b) forming a program as soon as possible and using it to suggest actions to the user, thereby curtailing free variation in performance of the task. Executing the program on successive examples and "debugging" it where necessary provides a natural way to extend it incrementally, thus avoiding the need to think in advance about problem definition; this fits the procedural model well.
Our pilot implementation has numerous shortcomings. Embedded in a "toy" editor, it has no pretensions to being a usable software tool. A decision was taken to simplify each component as much as possible in order to get a working prototype. For instance, in select actions the attributes are discarded and notice is taken of the selected text alone; this means that one cannot select by context. More generally, no serious attempt has been made to resolve the general question of conflict between constraints imposed by different attributes; this deserves further study. There are important deficiencies in the program-construction method, for despite its attempt to forbid ill-structured programs, the node-merging policy is rather simplistic and merges nodes far too readily, constructing spaghetti-like programs that produce anomalous behavior in all but the simplest situations. For instance, if the task in Figure 3 were extended with more examples of bibliography items having different formats (books with publisher and place of publication, papers in edited collections, etc.) the program construction method would effectively break down and useful predictions would cease to occur.
Some parts of the system rely on a lexical characterization of text that is essentially ad hoc. For example, attributes such as distance measures and position indicators are based on a division of the text into characters, words, lines and paragraphs. The string generalization method relies on a particular hierarchy of character classes. The definition of each of these units should really be sensitive to the type of text being edited.
Despite its shortcomings, the pilot implementation has demonstrated the viability of a procedural programming by demonstration approach to repetitive text editing. It provides a substantial amount of assistance in the three example tasks, as shown in Table 1, by learning the essence of the procedure on the first block of text and executing it on the remaining blocks, with only minor debugging being necessary.
User acceptance of programming by demonstration in this domain has not yet been studied. We believe that the procedural approach adopted here gives the best chance of rendering the system's operation as transparent and natural as possible to the user: it performs editing actions in sequence, like a person does, and looks for contextual cues to determine where to perform editing actions. However, this belief has yet to be tested.
Tasks within the domain: Reformatting textual data
Intended users: non-programmers
Types of examples: TELS learns from a single block of text which may
include several examples of some steps. Then, it incrementally generalizes or
modifies the constructed program as the user confirms or corrects subsequent
predictions. It generalizes character string patterns and procedures from
multiple examples.
If the user rejects a prediction, TELS treats the predicted text selection as a negative example: when searching, TELS skips over any selections that match a negative example.
Program constructs: Variables, loops, nested loops and conditionals.
Table of Contents Watch What I Do