
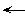 Table of Contents Watch What I Do
Table of Contents Watch What I Do
Figure 1 shows a sample task and dialog between Turvy and one of our users.
Figure 1.
c. Kate's transcript
Kate: Take the last name, it will be in some cases before a colon.
[Kate
copies "Agre", pastes it to a new paragraph, types brackets and sets the
style.]
This is a list of publications. Now we're going to add the last two
digits of the date [types "88"].
Do you want another demo?
Turvy: I can try if you want.
Kate: OK.
Turvy: Looking for word before first colon in next paragraph [picks "Andreae"], OK?
Kate: OK.
Turvy: [while doing actions] Copy, go to start of paragraph, OK?
Kate: OK.
Turvy: New paragraph, open bracket, paste, close bracket, change style to "citation", OK?
Kate: OK.
Now Turvy makes a mistake with the date. When Kate typed "88," Turvy found no instance of it in recent actions, so it assumed the number is a constant. Turvy always requires a demo to go with verbal instructions. After Kate shows the right action, it echoes back a new hypothesis.Turvy: Type in blank space "88", OK?
Kate: No, the last two digits at the end.
Turvy: Show me please.
[Kate picks digits.]
Two digits before period at end of paragraph?
Kate: Yes.
Turvy: May I continue?
Kate: OK.
This next example introduces a new case, multiple authors (see the third entry in Figure 1). Turvy's search pattern was "word before first colon in the paragraph," which selects the last author. Note that Turvy rejects the generalization "any punctuation" for two reasons: words before periods ("E.", "H.") were not given as examples; and Kate said "comma."
[Turvy picks "Smith"]
Kate: No - stop.
Turvy: Show me please.
Kate: I want the last name of the first author.
Turvy: I don't understand - show me please.
Kate: When you have a number of authors, choose the first [picks and copies "Andreae"]. It's before the comma.
Turvy: Word before first comma or colon?
Kate: Yes.
A little later on, Turvy comes to an entry in which the surname happens to precede the initials ("Michalski" in Figure 1). Turvy picks the last initial. Kate's hint "first word" does not repair the pattern, so Turvy proposes the pattern "word followed by 0 or more words ending period, followed by comma or colon".
[Turvy picks "S."]
Kate: No.
Turvy: Show me please.
Kate: I want you to take in this case the very first word [picks
"Michalski"],
then continue as before.
Turvy: You skipped back over words ending in period?
Kate: Yes.
Turvy: Continue?
Kate: OK.
Finally, Kate teaches Turvy to parse names with baronial prefixes ("van Lehn" in Figure 1). Turvy recognizes "case, select, last two words" in Kate's hint. "Case" suggests a new special case, or the case of the word. The latter explains "van Lehn," but the Wizard plays dumb. Turvy asks for some feature that completes the pattern: (0 or 1 of ??) followed by word before (0 or more words ending in period) before first comma or colon.
[Turvy picks "Lehn"]
Kate: OK, um, stop [hesitant]. In this case I want you to select the last two words.
Turvy: Show me please.
[Kate picks "van Lehn"]
What's different about this case?
Kate: Hmm [confused].
Turvy: You selected these two words, why?
Kate: Because these two words make up his last name.
Turvy: Is there some feature of that word [highlights "van"] I should look
for?
That word exactly?
Kate: [hesitant] In this case, yes.
In the dialog presented above, Kate's goal is to get Turvy to do the task (until a new case requires further teaching), and Turvy's goal is to get more specific information from Kate about what patterns to look for. Typically, Kate does one example, then Turvy does the next. When Turvy errs, Kate demonstrates the correction and maybe gives a hint; Turvy echoes back its interpretation. If Kate's hint is ambiguous, Turvy proposes a guess to elicit further explanation. This sample session also illustrates the role of the Wizard, who has to interpret Kate's actions and hints according to pre-defined rules, while using his discretion to make Turvy a little extra stupid if that helps gather more experimental data.
Turvy's domain knowledge and language understanding are quite primitive. We tested our simulated Turvy on bibliography editing tasks, but Turvy knows nothing about bibliographies. Users have to teach concepts like "surname" as syntactic patterns like "word before colon before italic text." Although a real instructible agent might have built-in knowledge about bibliographies, as in Tourmaline (Chapter 14), users in real situations will be teaching arbitrary new concepts, so we chose to test Turvy's ability to learn from scratch. Turvy's background knowledge, a collection of pattern matchers and generalization hierarchies for syntactic features, appears feasible to implement.
Turvy spots keywords and phrases in users' continuous speech. If the user says, "I want you to find surnames that come before a colon," Turvy spots only "find, before, colon." Turvy's knowledge of English can be implemented as a phrase thesaurus. Spotting phrases in continuous speech is problematic, although Apple Computer's "Casper" project shows promise in this direction.
Testing a simulated rather than a working prototype affords several advantages. First, the simulated prototype is very cheap to implement and easy to change. Second, various implementation details may be left out, with a canned script replacing computation. Third, a reliable, interesting commercial application can serve as the task environment. Fourth (and perhaps most importantly), the designer, in portraying Turvy, becomes directly engaged with the problems that users face, and is therefore more likely to understand them.
In the experiment, we invited a variety of people to teach Turvy six bibliographic editing tasks, ranging from trivial (replace underlining with italics) to taxing (put all authors' given names after their surnames). Users were allowed to invent their own teaching methods and spoken commands, but Turvy had pre-defined limits on inferences it could make and vocabulary it would recognize. We wanted see how people adapt to an agent that seems to learn like a human being yet has surprising limitations. Also, we wanted to find any regularity in the kinds of instructions people tend to give.
We found that users readily learned to speak Turvy's language and did not object to using it. Turvy's speech output was the most important factor in training them. All users employed much the same commands and used similar wording. Users formed two camps: talkative ones, who focused on interacting with Turvy, and quiet ones, who concentrated on their work. All users came to understand that Turvy learns incrementally, refining a concept as new cases arise. Thus they were content to give one or two demonstrations and let Turvy take over. Few subjects used pointing gestures to focus attention: when Turvy asked them to point at features they became confused. When it asked them to describe features they often did. But the best elicitation technique was to propose a guess: users almost always replied with the correct feature, even though they had no menu from which to choose and Turvy had not mentioned it.
When defining the model, we assumed that the sort of agent we could implement will have about as much background knowledge and only slightly better inference mechanisms than existing demonstrational interfaces like Peridot, Metamouse, TELS and Eager (see Chapters 6 through 9). The learning mechanisms we envisaged use knowledge-guided generalization to form an initial theory from a first example, followed by similarity-based generalization to refine it over multiple examples (for definitions of these machine learning terms, see the Glossary at the end of this book). Verbal and pointing hints would be used to focus the system's attention on features and objects, causing it to propose them in preference to others when forming generalizations, and possibly causing it to "shift bias" -- that is, to consider a different set of features.
* syntactic patterns, including constants and variables
* macros, sequences of application events
* conditional subtasks, rules that test search patterns and execute macros
* sequences of one or more conditional subtasks
* loops, repeating sequences
Turvy has two kinds of built-in background knowledge: an algorithm for constructing procedures; and application-specific knowledge about generalizing search and replace patterns. Turvy learns by matching observed features of examples with descriptions already in either its background knowledge or the model of the task it is learning. When generalizing, it matches multiple examples to background knowledge patterns that cover them. Hints help it choose among alternative patterns or try a pattern not directly suggested by examples. We worked through each of the six tasks, manually applying Turvy's knowledge to build a model. The model of Task 3 (taught by Kate above) is given below.
task CITATION-HEADINGS:
when user says "Make citation headings"
run T3-LOOP
loop T3-LOOP: repeat (EDIT-SURNAME EDIT-DATE)
conditional EDIT-SURNAME:
if find AUTHOR-SURNAME then do MAKE-HEADING
else TurvyAllDone
conditional EDIT-DATE:
if find PUBLICATION-DATE then do HEADING-DATE
else
TurvyAskUserForDemo
pattern AUTHOR-SURNAME:
Paragraph.Start SomeText (BARONIAL-PREFIX := 0
or more Word)
(SURNAME := Word)
(0 or more Word Period) /*
as in "Michalski R. S." */
(Colon or Comma) /* end of the
pattern */
where
Style(Paragraph) = "bibliography"
and
Capitalization(BARONIAL-PREFIX) = AllLowerCase
pattern PUBLICATION-DATE:
(DATE := Digit Digit) (0 or 1 Period)
Paragraph.End
macro MAKE-HEADING:
copy SURNAME demo select SURNAME,
copy
locate CurrentParagraph.Start demo put-cursor-at
CurrentParagraph.Start
insert "[" demo type "["
insert
SURNAME demo paste
insert Blank (DATE-LOC := "]") demo type
Blank "]"
insert Return demo type Return
set property
ParagraphStyle of CurrentParagraph to "citation"
demo select styleMenu,
select "citation"
macro HEADING-DATE:
copy DATE demo select DATE, copy
locate
DATE-LOC.Start demo put-cursor-at DateLoc.Start
insert DATE
demo paste
Contexts are patterns that trigger invocations (see Chapter 21); they comprise one or more system events (e.g. the clock reaches a certain time), application events (e.g. text is pasted), user commands (e.g. "Make citation headings"), or the selection or alteration of some pattern in the data (e.g. the user selects a telephone number). When learning a new task, the default context is empty, which means the procedure will not be invoked again. The context for the CITATION-HEADINGS task is the user-defined command "Make citation headings".
In the experiment we did not investigate the teaching of invocations. Turvy's heuristic for inferring them is to trigger a task on the event that provides the data to which the task refers. For instance, in Potter's "word paste" scenario (see the Test Suite appended to this book), the paste operation provides a string around which the task operates, so paste is inferred as the invocation. The user could replace this or specialize it (add a condition) by indicating other precondition events or by defining a verbal command.
Conditionals are sets of rules, like "if-then-else" or Lisp cond, that map search patterns to macros. They allow Turvy to handle different special cases in the data at each step of a task. When executing a conditional, Turvy matches each alternative search pattern with features in the data (e.g. "word before colon"). The first one to match fires (as in cond). If none fires, Turvy does some default action: ask the user for a demo, go on to the next subtask, or announce completion. A new conditional has the default TurvyAskUserForDemo (cf. Pygmalion, Chapter 1). When a task or loop ends, the last executed conditional's default is set to TurvyAllDone (as in EDIT-SURNAME above).
Turvy learns a new conditional subtask whenever the user selects data that must be found by searching, as opposed to data that is directly derivable. For instance, when the user selects the two digits at the end of an entry, Turvy cannot extend the search pattern AUTHOR-SURNAME to include them, so it creates a new conditional. On the other hand, when the user goes to paste them before the bracket in the heading, Turvy does not need a new search pattern to derive the insertion point, so that step is appended to the HEADING-DATE macro.
Turvy continually tries to predict, and learns new rules or modifications to existing rules whenever prediction fails. Turvy matches the user's demo with subtasks of the current procedure. If Turvy predicted the right macro but picked the wrong object (for instance, when it chose "Smith" instead of "Andreae"), it revises the search pattern. If Turvy fired the wrong rule, it specializes that rule's search pattern, or else creates a new special case rule to be tested at higher priority. If a rule does not fire when it should, Turvy generalizes its pattern. If no rule matches the current example, Turvy creates a new rule.
Loops are sequences of one or more subtasks, which may themselves be conditionals or loops. Turvy's loops emulate set iteration, repeating for all instances of a search pattern (strictly speaking, the search pattern in the loop's first subtask). The grammar for loops allows for counted iteration and for termination on some special event, but methods by which users might teach these controls were not tested in the experiment.
Turvy continually tests for repeated actions (cf. Eager and Metamouse). Two subtasks are considered the same only if both their search patterns and macros can be matched; macros are checked first, since they provide evidence for matching search patterns, which may need to be generalized.
A repeated sequence of actions implies either a loop or a subroutine. By default, Turvy predicts a loop (justified because Find&Do actions are large-grained subtasks). If it does not continue as predicted, Turvy forms a branch. (In the experiment, we did not explore the alternative of unfolding the loop.) If the user tells Turvy to stop repeating before it has processed all instances, Turvy asks whether the it should end on a count or special condition.
Macros are straight-line sequences of application events containing no loops or conditionals. Macros are parameterized, in the sense that they operate on the current instances of search patterns. Macros may also set variables, provided their values can be computed directly, without having to do a pattern match.
Each macro step is one of the basic editing operators supported by all applications (locate, copy, insert, delete or set property value), but Turvy also records the actual steps demonstrated by the user, since users expect it to imitate them. For instance, in the macro MAKE-HEADING above, the step "insert SURNAME" is paired with "(demo paste)." The reason for using more abstract operators like "insert" is to keep track of variable dependencies, which enables Turvy to match demonstrational sequences more rigorously: after all, any two "paste" actions are the same, but "insert SURNAME" and "insert DATE" are not.
Dealing with user errors. Users can tell Turvy to ignore steps they just did or are about to do. In the former case, Turvy asks the user to undo those steps. When the user undoes actions, Turvy forgets them and the data they referred to.
An augmented-BNF attribute grammar for text patterns is given in the Appendix to this chapter. Patterns consist of a sequence of one or more chunks of text bounded by defined delimiters and possibly having specific contents or properties, which are specified in a list of constraints (following the keyword "where" as in AUTHOR-SURNAME above).
Delimiters are punctuation marks, bracketing characters such as quotes and parentheses, word, line and paragraph boundaries, and changes in text formatting (capitalization, font, point-size, text style, subscripting, paragraph style). All tokens, formatting and delimiters within user selected text are parsed. If several delimiters beyond it run together (e.g. Colon Italics), Turvy records them all.
The properties of a text chunk are its string constant, length (which can be measured at different granularities: character, word, paragraph), and formatting. When learning a search pattern from the first example, Turvy ignores properties but records them in case needed later to specialize the pattern.
Variables point to chunks of text within patterns, so that Turvy may re-select or search relative to them. Patterns may set or test variables. Any sequence of elements within a pattern may be assigned to a variable and assignments may be embedded, for instance (BARONIAL-PREFIX := 0 or more Word) and (SURNAME := Word) in the pattern AUTHOR-SURNAME. Variables may appear in macros (e.g. SURNAME, which points to the text actually selected and copied) or property tests (e.g. Capitalization(BARONIAL-PREFIX) = AllLowerCase).
Learning from one example. When learning a new pattern, Turvy parses the user-selected string and its neighborhood, looking at delimiters and properties. If the pattern is deterministic (i.e. a search for that pattern would have selected the same text), analysis stops there; otherwise, parsing continues outward on either side of the selection. For instance, in the first example of Figure 1, the user selects "Agre": its pattern is Word, but that is nondeterministic since two other Words precede it. Turvy therefore scans outward and finds two delimiters -- Colon and format change to Italics -- so the search pattern is (Word Colon Italics). Turvy gives up after testing three runs of text between delimiters. If it cannot construct a deterministic pattern, it asks the user to describe or point to distinguishing features of the current or previous examples. Turvy is biased against forming patterns with string constants (e.g. "Agre"), resorting to them only if multiple examples or a user hint warrant.
Multiple examples. Like Tinker (see Chapter 2) Turvy learns incrementally, generalizing or specializing a pattern when it does not perfectly match the current example. If the search skips over a desired item, Turvy generalizes the pattern by dropping properties or outermost delimiters at either end of it. When the search selects something the user wants to skip over, Turvy specializes the pattern by adding properties or chunks of text and delimiters (as when constructing an initial pattern). Generalization and specialization succeed provided the resulting pattern covers the same set of examples; otherwise Turvy creates a new pattern for the current example (in machine learning terms, a new disjunct), using the method described above for learning from one example. Turvy always verifies a generalization, specialization or new disjunct by asking the user.
Focusing. The user can give verbal hints or point at items to be tested in patterns. If the user selects an object, saying "look here," Turvy tries to include it in the search, if necessary by extending the pattern across intervening text. If the user mentions an attribute, like "italics", Turvy adds it to the pattern as a delimiter or property. Anything the user suggests or confirms is given special status: Turvy will not discard it when generalizing, unless the user tells it to.
Turvy does not do full natural language understanding; instead, it spots keywords and matches them with examples actually seen. The user can state negations ("the text is not before a comma"): Turvy associates "not" with the next descriptive term and checks that it is not true of the example. A hint might refer to the past ("this case is different because the ones that came before, came before italics"). Turvy does not parse the sentence to associate features correctly; instead, it notes that "before italics" applies to previous examples but not this one (and would do so even if the user said simply "before italics").
On the other hand, Turvy tries to guide the teaching dialog by following some rules of discourse. First, it keeps silent while watching the user do an initial example, rather than interrupt the user with feedback regarding its initial pattern hypotheses. Second, Turvy lets the user know that it has matched an action (by saying "I've seen you do that before"), and offers to do the following steps ("Can I try?"). Third, it describes search patterns and asks for confirmation of actions when predicting them for the first time; on subsequent occasions it does them silently. Fourth, Turvy asks for confirmation when it generalizes a pattern to continue a task. Fifth, it asks the user to name features or point at objects when it needs to specialize a description.
The messages we predicted are given in Table 1. Most messages from the user have duals for Turvy, so that either party might lead the dialog. There are three broad categories of interaction: "Control" messages determine which party does which actions (learning operation a above); they indicate the structure of a task and therefore guide Turvy to match particular action sequences with one another (operation b). "Focus attention" messages also direct Turvy to try matching, and some indicate which features are relevant (operation c). Focus messages from Turvy to the user are prompts to elicit useful focusing directives in return. "Responses" are just brief replies to focus and control messages.
The proposed instructions assume no particular wording. Thus, Turvy can understand various formulations of a given command, or change the wording of its own utterances to suit the user. For instance, Turvy understands "Do the next one", "Do another", and "Try one" to mean "Do the next iteration." In the event we found that users adopted much the same wording for commands, and would imitate Turvy's wording (e.g. "Do the next one").
Table 1. Messages used in the study.
Control messages from User ... from Turvy
* Watch and learn * Show me what to
what I do do
* End of lesson * All done
Do the next step * May I take over?
* Complete this * May I continue?
example (iteration)
* Do the next * [May I] do the
example (iteration) next one?
* Do all * [May I] do the
remaining examples rest?
(iterations)
* Stop (you've
made a mistake)
~ Undo [one step or to ~ Undo [last step?] [this
start of iteration] iteration?]
* Ignore my
actions (I'm fixing
something)
1 Let me take over You take over
1 Always let me do these Do you want to do this
steps manually?
Focus instructions
1 I'm repeating what I did * I've seen you
before do this before
This is similar to * Treat this like
[indicates previous example] [describes similar item]?
This case is different ? What is different about
this case?
R Look here (this is ? Is this [describes item]
important) important?
* Look for * I should look
[describes item] for [describes item]
R I did this [conditional * Is this
branch] because [points at [describes feature] what
something and/or lists distinguishes the two cases
features] [or new special case]?
1 I'm changing the way I do You've changed the method,
this task why?
Responses
R OK / yes * OK / yes
R No * No
R I don't know / I don't * I don't know,
want to discuss that show me what to do
The Turvy experiment concerns an interface that learns tasks from demonstrations and verbal instructions. It differs from other experiments in the demands put upon the Wizard, who must portray an interface that learns complex tasks but is not supposed to have human-level capabilities or cultural knowledge. The key difficulty is managing a lot of information without appearing too intelligent; Turvy must seem to be focused on low-level syntactic details of the text.
We realized from the outset that it would be all too easy for the Wizard to slip out of character, despite our formal models. In order to sustain the simulation of algorithmic intelligence, we decided to minimize the amount of new information the Wizard has to cope with. Hence we had users do standard tasks on data the Wizard had prepared. Moreover, all tasks were designed to limit the user's options: there were no "inputs" (data was merely cut, copied, pasted) and few points at which the order of steps could be varied. Each task was analyzed beforehand, so that inferences made from examples (given in a standard sequence) could be rehearsed by the Wizard, who need only improvise when a user gave a novel hint, tried some unusual way of teaching, or made a mistake.
To collect more data on how users describe syntactic features, we had Turvy ask the user before offering its own hypotheses. We also made Turvy a little extra stupid (for instance, guessing "van" rather than lowercase in Tasks 3 and 4).
Users
worked through five or six tasks, teaching Turvy after short practice sessions.
Subjects were told that Turvy learns by watching, and that it understands some
speech, but they were told nothing about the sort of vocabulary or commands it
recognizes. The instructions for each task were carefully worded so as not to
mention low-level features that users might have to describe for Turvy. This
tested its ability to elicit effective demonstrations and verbal hints. We told
users up-front that Turvy was not a real system. To reinforce the fantasy,
Turvy spoke in clipped sentences with rather stereotyped intonation, and we
found that users quickly bought into the illusion. They spoke more curtly to
Turvy than to the facilitator, and referred to Turvy and the Wizard as two
separate entities.
We refined the experiment and Turvy's interaction model through iterative testing. Originally we did not plan for a speech interface: we ran a pre-pilot with the proposed facilitator acting as subject and communicating with Turvy via menus and keyboard. When it became clear that our user misunderstood the menu commands, we realized we ought not to predetermine the user's language. Also, the tasks were too complicated, and so we broke them down further. We then ran a pilot in which four people of varied professional background (management, psychology and hypermedia design) tested a speech version of Turvy. After some initial hesitation, they easily composed their own commands. Turvy would point at Word's menu items to indicate features it thought important (for instance, to propose "italics" it would pull down the format menu and select "* Italic"), and to elicit features it would ask very general questions like "What's important here?". These tactics confused the users; they did better when Turvy described its actions, made context specific queries, and proposed guesses.
We again refined the interaction model and then ran the main experiment on eight subjects (three secretaries, four computer scientists, and one psychology student). Turvy's behavior was held constant, but when the wording of a question caused consternation, Turvy would reword it, adding or removing contextual details. Thus the interaction model was further tuned throughout the experiment. We collected interviews, audio, and video from the pilot and experimental sessions. To corroborate our observations and the users' statements, we did a content analysis of the instructions they gave Turvy.
To generalize the results, we did a pilot study on other task domains: file selection and graphical editing, tested on three and two users respectively.
The figures illustrate samples of data for each task; the original data is to the left of the dividing line, the result is to the right.
Figure 3.

Figure 4.

Note: Task 3 (in which the user puts the first author's surname and last two digits of the date into a heading for each entry) appears in Figure 1 near the start of this chapter.
Figure 5.

Figure 6.


We had four main working hypotheses, concerning the suitability of the inference and interaction models, the use of a speech-based interface, and the ease of teaching an agent.
1. All users will employ the same small set of commands, namely those given in Table 1, a subset of the interaction model. They will do so even though told nothing in advance about the instructions Turvy might understand.
2. Users will learn "TurvyTalk" (Turvy's low-level terminology for describing search patterns), but only as a result of hearing Turvy describe things. Users will adopt Turvy's wording of instructions. (This hypothesis is based on a theory of verbal convergence between dialog partners [Leiser 89].)
3. Users will point at ranges of text other than those they must select for editing, to focus Turvy's attention on relevant context for the search pattern they are teaching.
4. Users will teach simple tasks with ease and complex ones with reasonable effort. In particular, in complex tasks, users will not try to anticipate special cases but instead teach them as they arise.
The typical talkative user begins by describing the task in words. Turvy says, "Show me what you want." The user performs a single example and asks Turvy to try the next one. Turvy does it, describing each step and asking for confirmation. If it makes no mistakes, Turvy asks permission to do the rest. When it does err, the user cries "Stop" and may then tell it what to do. Turvy says "Show me what you want," and the user does the correction. Turvy asks for features distinguishing this case from the predicted one. Initially it asks vaguely, "What's different about this example?" If the user is puzzled, it says "Can you point to something in the text?" If that doesn't work, it proposes a description.
A quiet user works silently through the first example and goes on to the next one without inviting Turvy to take over, nor even signaling that the first example is complete. When Turvy detects repetition, it interrupts, "I've seen you do this before, can I try?" The user consents, and the rest of the dialog proceeds much as for talkative users, except that a quiet one is more likely to tell Turvy to skip a troublesome case than try explaining it.
In the post-session interviews, we found that both types of user formed similar models of Turvy's inference and interaction. They recognized that Turvy learns mainly by watching demonstrations, but that it understands verbal hints. All users liked Turvy's eager prediction, because they this reveals errors before they become hard to correct. Some talkative users had difficulty at first because they thought they should try to anticipate special cases and give Turvy a complete task description, but they learned, like the quiet ones, that it was better to wait for special cases to arise. All were concerned about completeness, correctness and autonomy; they believed it would be foolhardy to leave Turvy unsupervised.
From the table we see that nearly all control instructions were used and caused no difficulty. Most users gave most of these instructions. The actual wordings they used varied little, especially after they heard Turvy ask the corresponding question -- they would drop "May I" and turn the rest of it into a command, such as "Continue" or "Do the rest."
Instructions for focusing attention were problematic. Users almost never volunteered vague hints like "I'm repeating actions," "this is similar," and even "look here." On the other hand, they gave hints in answer to questions from Turvy. The wording of focus instructions was more variable.
In the post-session interviews we asked users about the kinds of terminology Turvy understands. They had some trouble answering so vague a question, but when we gave specific examples, nearly all subjects clearly understood that Turvy looks for and understands descriptions of low-level syntactic features rather than bibliographic concepts. Two subjects thought it might know something about the formatting of names and dates.
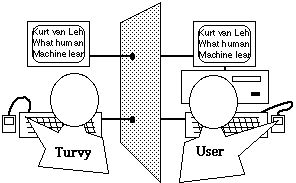
To confirm these observations we did a content analysis of users' speech. We divided the session into 15 events, corresponding to different phases of tasks such as the first example and points where Turvy would habitually err (such as the "Michalski" and "van..." entries in Tasks 3 and 4). We excluded Task 5 for lack of data. We counted the number of user instructions that referred to features in terms Turvy could understand (e.g. "paste after the word before a colon") versus those that involved bibliographic terminology (e.g. "paste after the author's name"). If a single instruction contained both kinds of terms, it was counted under both categories. We did not count the number of words or features referred to in a single instruction, since that might be arbitrarily large and would tend to bias towards the more verbose TurvyTalk; rather, we counted instructions (as defined in the discourse model).
A summary of the average counts for experimental subjects is shown in Figure 8. Although TurvyTalk naturally dominates when describing text formats, it also comes to dominate even where tasks involve concepts like titles, names and dates. The use of user concept terminology tapers off as the session progresses. More interesting is the tendency to combine both forms of speech, as in events 4, 7, etc.: this corroborates our informal observation that users tended to try to relate their concepts to Turvy's by using both languages in the same instruction.

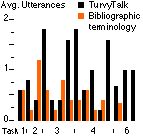
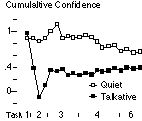
In the graph, the use of TurvyTalk seems to dominate from early in the session (even discounting task 1). We surmised that this was because Turvy's verbal feedback quickly trained users to mirror its language. Figure 9 shows a cumulative average of TurvyTalk minus bibliographic concepts computed for both pilot and experimental subject groups. The running sum is divided by the number of events (so far) in which the user concepts count is non-zero. This measurement has the following nice properties: co-occurrences of user concepts and TurvyTalk cancel each other out; events at which user concepts dominate are highlighted by a sudden drop in the score; and events containing small amounts of TurvyTalk but no user concepts increase the score. A score above zero indicates that TurvyTalk is dominating overall.
The dominance scores indicate that experimental users made more use of TurvyTalk than the pilot users (who received less verbal feedback). It should be stressed that the graph merely corroborates our observations; the small number of subjects and high variability make statistical inferences unwarranted.
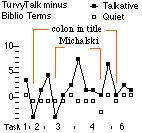
We also compared the dominance of TurvyTalk in talkative versus quiet users. Figure 10 shows the TurvyTalk minus user concept counts for each event. Although TurvyTalk dominates more in talkative subjects overall, note that when problem cases first arise (colon in title, Michalski) the talkative subjects lapse more deeply into their "native" language. Perhaps the most interesting point, however, is that on the second occasion they use more TurvyTalk.
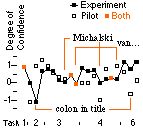
In the post-session interviews, all subjects reported that they found Turvy easy to teach, especially once they realized that Turvy learns incrementally and continuously, so that they need not anticipate all special cases.
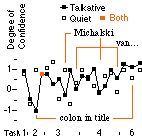
We tried to objectify users' impressions about the ease or difficulty of teaching Turvy by doing a content analysis of certain speech characteristics. We treated occasions on which the user told Turvy to "do the rest" as indicators of high confidence (C in the formula below). Normal responses were treated as positive control (P). Long pauses or words like "umm" indicated hesitation (H). Questions about the meaning of Turvy's actions, verbal stumbling and confusion indicated a loss of confidence (X). We counted such events over each of 20 intervals in the session (once again excluding Task 5). A "degree of user confidence" measure was computed as a weighted sum of the counts, 2C + 1P - 2H - 4X which was normalized by dividing by the total C + P + H + X. Note that we devised this formula to reveal trouble spots in the interaction traces: we chose weights that bias the score towards negative measures, so it tends to emphasize any loss of confidence. Figure 11 shows levels of confidence over each interval of the session, averaged for pilot and experimental users. Events at which users deal with more complex patterns clearly cause the greatest anxiety, but the experimental group seems to suffer less as the session progresses.
We also compared talkative versus quiet users, as shown in Figure 12. A curious feature of this graph is that the two groups drop into confusion at slightly different points relative to first encounters with tricky cases. The quiet group loses confidence just before the difficulty arises, as if anticipating it. Note also that quiet users tended to tell Turvy to skip a difficult case rather than explain it. Towards the end of the session, both groups are synchronized, with talkative subjects appearing somewhat more confident.
If we compute a progressive average measure for quiet versus talkative users, we get the curves shown in Figure 13. This shows quiet users starting out with an advantage, perhaps due to their strong focus on the task and lack of interaction with Turvy. The talkative users, after recovering from the initial shock of answering Turvy's questions in task 2, slowly increase in confidence. The quiet ones gradually lose their advantage, perhaps because they are not learning as much TurvyTalk (compare with Figure 10).
All experimental users and all but one pilot user said they would use Turvy if it were real. They liked the way it learns incrementally and they did not mind answering a few questions. They believed they would have difficulty coming up with low-level syntactic descriptions entirely on their own. They liked the way Turvy described actions while doing them the first time; they did not notice that it works silently on subsequent iterations.
One pilot user rejected the very idea of an instructible agent and refused to work with Turvy. This person believed that a user would have to anticipate all cases of a pattern in advance, as when writing a program. We were unable to entice this user to go through the Turvy experience.
Further experiments should be done, focusing on difficulties with procedural constructs (such as whether a repeated sequence represents a loop with internal branching or a subroutine). Turvy has been pilot tested in graphical and database domains, with similar results, but further testing is warranted, especially on the teaching of replacement and constraint patterns.
The version of Turvy tested in the experiment had some limitations designed to elicit more experimental data; for instance, Turvy's inability to re-use concepts in later tasks. The inference and interaction models should be extended to address ways that Turvy can re-use patterns, and ways that users can name or invoke them (see also Chapter 21). Some forms of learning about learning are also suitable for Turvy. In the current design, some features are adopted in preference to others; this preference ordering could be adjusted based on the actual observed frequency of relevance. The chunking of features that appear often together in patterns would also improve Turvy's inferences.
We found that people can learn to communicate with an instructible system whose background knowledge concerns only low-level syntactic features. Users learned to speak to Turvy by using their social skills, imitating the way it speaks. All users adopted much the same commands, a subset of those we predicted; moreover, they used similar wordings. These two results suggest that a speech-based interface may be both feasible and preferable. Speech is being tried in another PBD system, Mondrian (see Chapters 16 and 24).
We found that, once users had become familiar with Turvy, the difficulty of teaching corresponded with the difficulty of the task. There were no peculiar features of Turvy that caused users difficulty (in contrast to Metamouse).
The "Wizard of Oz" method proved effective for gathering qualitative data quickly and cheaply. The quantitative results are rather suspect, due to the small population and high variance, but the most important observations, such as large increases in user anxiety when certain special cases arose, were highly consistent. The measurements did agree with opinions given by the users.
Perhaps the most important aspect of the experience was the "training" the designer received in the guise of Turvy. Being personally responsible for a test user's discomfort and confusion motivates thoughtful redesign!
The key risk in using the "Wizard of Oz" method to prototype a system as complex as an instructible interface is that the Wizard will apply more intelligence than he or she is aware of, and thereby obtain inappropriate, optimistic results. We tried to avoid this by analyzing tasks with fairly detailed formal models beforehand. Nonetheless, it remains to be seen whether a fully functional Turvy can be implemented. Handling verbal input and output are likely to be the most difficult problems, and the first implementations will be more primitive than the simulation in this respect. But the ability to learn from multiple examples and focus attention according to user hints should be sufficient to make Turvy an effective instructible interface.
Context ::= [ UserCommand | UserAction | SystemEvent |
PatternFound | PatternUpdate ]*
Sequence ::= [ Loop | Conditional ]*
Loop ::= loop Name: repeat ( Sequence )
{ LoopCount times | until
Context }
LoopCount ::= Number | UserSpecifiesCount
Conditional ::= conditional Name:
Find&Do {else Find&Do}* else
TurvyDefaultAction
Find&Do ::= if find *Pattern*Name then do *Macro*Name
Macro ::= macro Name: Command {; Command}*
Command ::= Operation { (demo AppCommand* ) }
Operation ::= [ ( locate | copy | insert | delete ) *Variable*Name ]
|
set property *Property*Name of *Variable*Name to Value
TurvyDefaultAction ::= [TurvyGoTo *Conditional*Name] | TurvyAllDone |
TurvyAskUserForDemo
UserCommand ::= user says UserDefinedCommandWord
UserAction ::= user does ApplicationEvent DataSpecifier
DataSpecifier ::= DataType | DataType in *Pattern*Name |
*Variable*Name
SystemEvent ::= system event *Event*Name
PatternFound ::= pattern *Pattern*Name found
PatternUpdate ::= pattern *Pattern*Name changed
{ to match
*Pattern*Name }
Rules of inference for a conditional. When the user rejects a predicted action (including the default action TurvyAllDone), Turvy repairs the conditional that generated it, generalizing or specializing the search pattern and if necessary adding a new branch The rules of inference are given below. Suppose the user has rejected Turvy's execution of alternative X in conditional C.
1. If the user's demo matches X's macro but not its search pattern, Turvy generalizes or specializes the pattern so that it selects the correct object.
2. If the demo matches another rule R, Turvy specializes X's pattern, and if necessary generalizes R's pattern, so that R would fire instead.
If R is in some other conditional K in the current task, Turvy sets C's default to TurvyGoTo K (that is, Turvy should proceed to step K of the task).
3. Otherwise, Turvy adds a new rule N to C, and specializes X.
(Note that Turvy does not check other rules in C to ensure that they do not fire in conflict with R or N; Turvy will wait until such an error arises before attempting to fix it.)
When no rule fires and Turvy asks for a demo, the following rules are applied.
4. If the demo matches some rule R in C, Turvy generalizes R so it would fire.
5. If the demo matches a rule in some other conditional K in the current task, Turvy sets C's default to TurvyGoTo K.
6. Otherwise, Turvy adds a new rule N to the conditional C.
The grammar for syntactic search patterns is given below.
PatternExpr ::= Assignment | SubPattern
Assignment ::= `(' VariableName := SubPattern* `)'
SubPattern ::= Disjunct | CountedItem | PatternItem
Disjunct ::= PatternItem [ or PatternItem ]*
CountedItem ::= Number {x | or more | {or | -} Number } PatternItem
PatternItem ::= DefinedItem | Token | StringConstant
DefinedItem ::= VariableName | Delimiter
Delimiter ::= Punctuation | Bracketing | Separator | FormatChange
Separator ::= WhiteSpace | StartOfLine | EndOfLine |
StartOfParagraph | EndOfParagraph |
StartOfDocument |
EndOfDocument
Token ::= Paragraph | Line | Word | Character
Constraints ::= TestExpr {and Constraints}
TestExpr ::= Test( Variable {, Variable}* ) = Value
Intended users: End users
Feedback about capabilities and inferences: Turvy announces when it first matches an action; describes search patterns; describes generalizations.
Types of examples: Multiple examples, Negative examples.
Program constructs: Variables, loops, conditionals.
Table of Contents Watch What I Do