
 Table of Contents Watch What I Do
Table of Contents Watch What I Do
Part of the problem stems from the limited amount of information the mouse can convey. The point and click style of interaction restricts the user's ability to successfully demonstrate their intent, which in turn causes ambiguity. As a result, other means for specifying detailed information, such as dialog boxes, pop-up menus, gravity points, grids, and keyboard input, have been invented. While these alternatives offer a solution to the problem, their use is often unnatural. Keyboard input requires that the user put down the mouse in order to type. Dialog boxes interrupt the user's concentration by forcing them to switch back and forth between different modes of interaction. To make matters worse, using these secondary methods can be just as ambiguous. For example, when using a grid to align two objects, should a system infer that the objects are positioned at grid unit (X, Y), or aligned relative to one another? If a menu command is chosen, does the system record the action of selecting the operation as part of the demonstration?
Having recognized this problem, some systems will employ interactive techniques such as snap-dragging [Bier 86] and semantic gravity points [Lieberman 92b] to disambiguate mouse input, instead of using a secondary method. Interaction techniques which can be used while the mouse action is taking place may provide a more natural and effective solution, since they allow the user to indicate intent in a way which does not disrupt them from their primary task.
One such technique is voice input. This chapter highlights an experimental extension to the Mondrian system described in Chapter 16. It explores the potential of voice input as a convenient means for disambiguating intent by allowing users to control how the system interprets their mouse actions.
Typical uses of voice input have included tasks which replace mouse commands altogether. Users will issue a voice command to close a window rather than clicking its close box or for selecting menu items and icons in the same manner. While operations such as these provide an alternative to mouse interaction, they do not utilize the full range which multimodal input devices can accommodate. Maulsby's proposed use of audio, as a tool for giving verbal hints about what features a system should focus on during a demonstration, in his Turvy experiment described in Chapter 11, begins to touch upon the potential of voice input.
One of the powerful advantages voice input has over secondary methods such as dialog boxes, is its ability to work in parallel with the mouse. When using mouse input, users are restricted to performing operations in a sequential order (Figure 1). Voice commands, on the other hand, can be defined as a sequence of operations, and issued while a mouse action is in progress (Figure 2). As each command is given, the system uses it to modify the current mouse action, allowing users to customize a general operation, such as "drawing a rectangle," into a highly specific, intentional action, such as "drawing a rectangle centered on the screen, with the dimensions 20 pixels by 200 pixels." Several voice commands may be given during an operation, to describe specific parts. Users can invoke a drawing operation, issue one command to take care of an alignment problem, then another to indicate an object's dimensions. The more specific the voice commands become, the less likely it is that the system will misinterpret the mouse action's intent.
At present, Mondrian only contains drawing routines for colored rectangles. In the following example, we will assume that the system's graphical language also includes text. The designer will use voice input to control the size and positioning of the graphical objects drawn while demonstrating the example, and as a means of informing the system that the distinct geometric relationships between the objects, stated above, should be noted when defining the procedure.
Figure 2. Voice commands used to size and align an object.
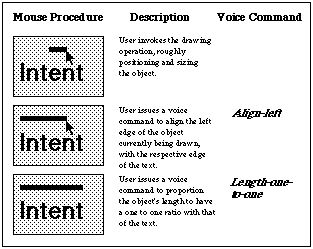
To start, the designer creates the title object "Intent," selects it, and informs the system that the demonstration is about to begin. By initially selecting the title, the system, by default, uses it as a "reference" point, checking for relationships between it and other objects created or selected during the course of the demonstration.
Next the designer begins to draw the top rulebar. Since its position should be left aligned with the title, the designer issues the voice command "Align-left" while still drawing (Figure 2, top). The system reacts by automatically extending the left edge of the rulebar, which originally was not aligned, to be perfectly aligned with the respective edge of the title (Figure 2, middle). In addition to aligning the top rulebar, the designer would also like its length to equal that of the title. To do so, the designer issues another voice command "Length-one-to-one," and the system replies by automatically finishing the drawing operation with the appropriate dimensions (Figure 2, bottom).
Figure 3. A layout with distinct stylistic relationships.

In a similar fashion, the bottom rulebar is created. Since its horizontal position should be centered with the title, the designer invokes the drawing procedure and issues the voice command "Align-center." Finally, one last voice command, "Length-200," is issued to appropriately size the bottom rulebar's length.
Having demonstrated to the system the relationships needed to create a layout in this style, the designer informs the system that this is the end the demonstration.
Built into Mondrian is a fixed set of heuristics for inferring spatial relationships such as "above," "below," "left," "right," "centered," and dimensional relationships such as "half-of" and "one-to-one." Yet, the system only invokes these heuristics if the drawing or positioning of two arguments, given a tolerance value, is equal. During the demonstration, when the designer began to draw the top rulebar, its left edge was not close enough to the title's edge for the system to recognize this relationship, hence a voice command was needed.
Figure 4. Re-application of the layout function on new arguments.

If the designer now performs the layout function with new arguments (Figure 4), all objects, with the exception of the bottom rulebar, are drawn with their dimensions and position relative to their own title object, rather than to the original one used to define the procedure. Since the designer wanted the bottom rulebar's length to be fixed, a voice command describing its dimensions in terms of an absolute numeric value (i.e. "Length-200") rather than a relative one was issued. If the designer had drawn the rulebar without issuing any voice commands, by default, the system would have tried to generalize the dimensions to be relative rather than absolute, which is not what the designer had intended.
The voice input resolved the ambiguities by modifying how the system interpreted the action, which forced it to invoke the appropriate heuristics, as though the user had performed the action in such a way that would cause the system to automatically trigger it. As the system was recording the designer's action, it literally incorporated the voice commands into the internal representation it was defining. The command "Length-one-to-one" which was initially translated into "one times the title's length" to perform the immediate operation correctly, was then generalized to be "one times any title's length" so that it would properly work on other analogous examples. Similarly, the designer issued the command "Align-left," to inform the system that it should view the object's position as being "aligned relative to the title," rather than at a certain set of coordinates, thus altering how the system remembered that action. By using voice input while the mouse action is taking place, users can effectively control how the system interprets and remembers their actions.
Depending on the scope of its use, voice input can often pose more problems than other means of input for several reasons. In the Turvy experiment described in Chapter 11, users actually said they would rather select from a menu or dialog box than use voice input since they did not trust the capabilities of the voice input device. Recognition of audio sounds in some systems is often poor, and misinterpretation of the voice commands can potentially be worse for input than menus since the failure rate is often higher, and worse than keyboard entry since typing has the advantage of being more forgiving. Using voice input also involves three levels of interpretation: the actual audio sound, its English translation, and its representation as a computational action. In systems which use a rich vocabulary of voice commands, users also have the problem of remembering the commands and knowing which terms they are allowed to say.
The other serious problem with using voice input, is that the voice commands themselves may be ambiguous. Depending on what they are defined to do and the order in which they are issued, their use can result in more ambiguity than other methods. In Mondrian, the default behavior of the system is to establish relationships between the reference point and other objects. If this method was not employed and the user issued the voice command "Align-left," how would the system know what and where to align it to? What if the user issued two conflicting commands, "Align-left" and "Align-center" or issued them in the wrong order? Should the system default to performing and remembering these commands sequentially? If so, then the advantages to using voice input would be no different than that of existing secondary input methods.
Since Mondrian runs in the Macintosh Common Lisp environment, the voice commands' actions were defined as Lisp functions. When the voice commands were executed, their actions were expanded into low-level function calls which were sent to a buffer, enabling the system to directly copy the buffer and evaluate it.
Table of Contents Watch What I Do