back to ...  Table of Contents Watch What I Do
Table of Contents Watch What I Do
Chapter
25
Characterizing PBD Systems
Allen Cypher,
David S. Kosbie
and
David Maulsby
Introduction
In the introduction to this book, we presented to the reader the idea of
Programming by Demonstration, indicating what PBD is and why it
is desirable. In this chapter, we take the discussion further, considering
how a PBD system is composed. That is, we lay out the various salient
dimensions that distinguish PBD systems. The purpose of this is two-fold.
First, readers can use this chapter as a framework for evaluating and comparing
systems. Second, designers can use this chapter as a model for presenting their
systems and as a means of delineating how their systems contribute to the
field. The summary sheets located at the end of each chapter in Section I are
based on this characterization.
We characterize PBD systems along the following dimensions:
- Uses and Users What is the application domain and who are the
users?
- User Interaction How does the user interact with the PBD system to
create, use, and modify programs?
- Inference Given the inherent ambiguity in inferring a generalized
procedure from a limited set of examples, how does the PBD system select an
interpretation for the user's demonstration?
- Knowledge What information can the system use in making
inferences?
The remaining sections of this chapter explain these dimensions
in detail.
Uses and Users
Application domain
Some systems, like TELS and Metamouse, are designed for a particular
application domain, such as word processing or graphical editing. Sometimes the
domain is quite specialized: Tourmaline contains a PBD system designed
specifically for text styles, and the Predictive Calculator handles arithmetic
calculations. Systems like Rehearsal World define their own domain, since they
are built as an integral part of a special-purpose environment. In contrast,
SmallStar works across the many varied domains of the Star workstation, and
Eager, Triggers, AIDE and KATIE are application-independent.
Intended audience
The design of a system interface is heavily influenced by the designer's
conception of the audience. While some of the earliest systems were intended
for use by programmers, SmallStar and Rehearsal World started the movement to
create systems for non-programmers. Mondrian was designed specifically for
visual thinkers.
The expertise of the users is another factor that influences design. User
expertise can be considered both with respect to the application domain, and
with respect to the PBD system. It is interesting to note that most of the
systems in this book assume experience in the application domain, although The
Geometer's Sketchpad is intended for students of geometry, and Tinker is
designed for beginning programmers.'
Systems also differ in their expectations of the user's expertise with the PBD
system itself. Eager, for instance, is explicitly designed to be usable without
instruction. while most of the other systems require some training or
experience.
User Interaction
User interaction with a PBD system comprises creating, invoking, executing,
viewing, debugging and modifying programs. Highly interactive systems, like
Metamouse, TELS and Tinker, tightly interleave program creation with program
execution, whereas macro-like systems, such as Chimera's macros by example,
generally have a separate execution phase which can take place well after the
macro has been created.
Chapter 8 (TELS) points out the practical value of designing for the
incremental development and modification of programs. Given the great degree of
inconsistency in real-world tasks that we consider "repetitive", it can be very
useful to allow for constant interaction between the user and the program, so
that there is no clear distinction between creating a program and using and
modifying it.
Creating programs
The common element uniting the systems in this book is that users create
programs through demonstration. A typical way to create a program is to turn on
a recorder, as in Pygmalion, SmallStar, Rehearsal World, Mondrian and AIDE. The
Predictive Calculator and Eager are a bit different in that they are always
turned on, and they monitor for repetitive activity. Chimera has a graphical
history that is always on, and that the user can view to select commands to
convert into a program.
Several systems offer alternatives to recording. In Tourmaline, the user
presents a previously-created style to the system. And in The Geometer's
Sketchpad, the user creates a program by making a geometric construction.
Guiding the generalization process
In addition to performing demonstrations, users also communicate with the PBD
system to guide the generalization process. In systems without inferencing, the
user explicitly specifies all generalizations. Other systems try to infer the
user's intent, and the user provides information to guide the inference
process. While the user is certainly an excellent source of information about
user intent, the human-computer interaction must be handled carefully. Direct
queries may be obtrusive, and furthermore, it may be difficult to pose
questions in a manner that is comprehensible to the user. The systems in this
book offer a variety of approaches to interacting with the user to create and
verify inferences. Inferencing is typically used for two kinds of abstraction:
creating data descriptions for objects, and adding program constructs such as
loops and conditionals.
Data descriptions Whenever the user selects an object in a
demonstration, the PBD system must determine why that particular object
was selected, so that when the program is invoked in the future -- in a
different context -- the appropriate object will be selected. A data
description specifies how to select the appropriate object. The description
might be "the rectangle created in the previous step", "the first word in the
current document", or "a button named SEND". SmallStar has the user
explicitly select a data description from a description sheet of predefined
alternatives. A similar approach is used in Chimera's MatchTool 2, where the
user specifies search properties by selecting them from a list. AIDE offers a
search dialog which gives the user a fair amount of flexibility in specifying a
data description. Chimera's macros by example facility infers several possible
data descriptions and uses heuristics to select a most-likely interpretation,
but the user can view the descriptions and select a different one. Peridot and
Metamouse also choose a single interpretation, but they query the user in
English before applying it. Eager chooses a single interpretation and presents
it to the user by highlighting objects on the screen. Lantern [Lerner 89]
chooses a single interpretation and performs it without asking, but then
observes whether the user undoes the action.
Tinker offers an interesting alternative: it presents the user with an Object
List which lists an object's name paired with its corresponding data
description. The user can select an object by name, and at the same time see
the corresponding data description that Tinker will use in place of that
object.
Program constructs The systems in this book present a variety of
interaction techniques for adding loops and conditionals to programs created by
demonstration. Pygmalion has special commands for looping and branching. In
SmallStar, the user inserts loops and branches manually into a previously
recorded program. The Predictive Calculator, Peridot, Metamouse, Eager, Turvy,
and AIDE all use inferencing to automatically detect the need for loops or
conditionals. They differ in how they ask the user to verify these inferences.
Feedback
Another user interface issue for PBD systems is how to convey to the user an
understanding of what the systems are doing and why they are doing it, as well
as an understanding of what they can and cannot do. Appropriate feedback
enables the user to monitor the system's behavior and to form a reasonable
model of how it operates. For instance, Mondrian informs the user of its
inferences via synthesized speech. Peridot and Metamouse query the user about
every inference and require Yes/No responses. The Eager interface reflects the
capabilities of the underlying system in that the Eager icon will not appear
unless it is able to completely automate the current task. Metamouse displays
black tacks to show intersections that it guesses are significant.
In addition to making users more aware of the inference process, PBD systems
can give users some control by allowing them to turn inferencing on or off, to
specify whether they want to be queried to confirm inferences, and to specify
how confident they want the system to be before it makes an inference. Garnet
offers the user some of these options. A further discussion of feedback can be
found in Chapter 26.
The preceding discussion focused on human-computer interaction during the
creation of a program by demonstration. We now turn our attention to the
other phases of interaction with a PBD system: invoking, executing, viewing,
modifying and debugging programs.
Invoking programs
Often users want to invoke their programs by selecting them from a menu or by
attaching them to a button. Pygmalion lets users create new icons, and Mondrian
allows users to create new "dominoes" in the program's command palette.
Rehearsal World provides several options for invocation by allowing the user to
attach a program to an object's Change Action, Button Action, or Repeat
Action.
Certain types of automation are only effective if their programs are invoked
automatically when a certain situation occurs. Systems that maintain graphical
constraints, such as Peridot, Chimera's constraint-based search and replace,
Chimera's constraints from multiple snapshots, Geometer's Sketchpad, and
Garnet's Lapidary are especially effective at automatic invocation. Whenever a
constrained object is modified, constraints are invoked to maintain
relationships. For instance, a program that keeps a line attached to a box in a
drawing of an "org chart" needs to be invoked automatically whenever the box is
moved. '
Chapter 21, "PBD Invocation Techniques", and Chapter 27, "Just-in-time
Programming", offer further discussion of invocation.
Controlling the execution of programs
Much of the success of a PBD system depends on the degree of control that the
user has over program execution. Some systems, like SmallStar, allow the user
to execute the program one step at a time. To accommodate tasks that are not
completely uniform, PBD systems may allow for "user actions" -- steps where the
system transfers control to the user, so that the user can manually perform
some actions. Pygmalion, Tinker, the Predictive Calculator and Metamouse all
stop and transfer control to the user when they do not know what to do.
Users also gain control over execution if they are able to undo incorrect
actions. Chimera and AIDE have infinite undo capabilities. Eager offers to save
a copy of any document that it is going to modify.
Viewing programs
There are a variety of reasons why users need to be able to view their
programs: to verify that the created program is indeed what they intended, to
review it at a later date to remember what the program does, and to edit the
program to fix problems or to incorporate additional features. To date, PBD
systems have been rather weak in their ability to present programs to the user.
Pygmalion presents a program as a movie, Rehearsal World uses Smalltalk,
SmallStar uses a scripting language that includes icons, and Eager uses
anticipation. Chimera offers a graphical history that presents actions in a
form that is recognizable to the user. Chapters 15 and 19 describe this
graphical history mechanism. One limitation of a graphical history is that the
representation may not be sufficient for expressing generalizations: it does
not specify the data descriptions associated with objects, and it may not
specify flow of control. The PURSUIT system, described in Chapter 20, addresses
many of these problems.
Modifying and debugging programs
Custom programs are particularly useful in situations where tasks are
continually changing and where special cases arise frequently, as in office
procedures. For PBD systems to accommodate this need effectively, it should be
easy for users to not only create their programs by demonstration, but to
modify the programs by demonstration as well. This could lead to a very natural
and effective style of program creation where the user demonstrates a basic
program that handles simple needs, and then incrementally adds coverage and
complexity as the uses of the program expand and change. Chimera's constraints
from multiple snapshots facility allows the user to add a new configuration by
taking an additional snapshot. Pygmalion, Tinker, the Predictive Calculator,
Metamouse, and TELS all offer some form of interactive development. This
conveniently integrates debugging with program modification. The Geometer's
Sketchpad presents a novel perspective on debugging: programs are debugged by
dragging objects into different configurations to test their behavior on
different "inputs".
One difficulty with modifying a program by demonstration is that later steps in
the program may no longer be valid. Pygmalion accounts for this by allowing
programs to be modified, but by then requiring that the remainder of the
modified branch be re-demonstrated. In contrast, SmallStar and Chimera's macros
permit any modification and do not check for validity.
Systems like Peridot and Tourmaline infer programs by looking at graphical or
textual objects, and the user can modify the programs by editing the graphical
or textual objects on the screen. This allows for program modification without
the need for a visual representation of the script.
Inference
Central to any PBD system is the transformation of specific demonstrations into
general programs that capture the intent implicit in the user's actions. Some
systems -- Pygmalion, Tinker, Rehearsal World, SmallStar and Triggers -- do not
infer the user's intent: they require the user to explicitly specify the
appropriate abstractions. In Pygmalion, the user must plan ahead and introduce
a conditional branch at any point that will have alternative paths in future
uses of the program. In SmallStar, the user chooses the appropriate data
description for an object from a list of alternatives.
The alternative to asking for explicit abstractions is to infer the
user's intent. An inference engine performs the actual computations
involved in generalizing, and a knowledge base contains the information
that the inference engine uses in its computations.
Inference engines
Each of the chapters in Section I describes its inference procedure in detail.
Here we will briefly summarize a few of the approaches used.
Peridot's inference engine examines its knowledge base of condition-action
rules. If the condition applies to the current context, the user is asked if
the rule should be applied. If so, the action part of the rule is applied,
adding a graphical constraint to the procedure. For instance, the
"centered-horizontally" rule has a condition which checks whether a
newly-constructed rectangle lies within another rectangle, and if the margin on
each side is about the same. The action part of the rule establishes a
constraint so that the sides of the inner rectangle will always be located this
fixed distance from the sides of the enclosing rectangle.
The Predictive Calculator keeps a history of all k-token sequences typed
into the calculator (k is a fixed integer -- in the experiments
described in Chapter 3, k = 4). Whenever the user types three tokens
that match a previously recorded sequence, the Predictive Calculator predicts
the fourth. Any sequence of digits is considered to be one token, representing
a number, and any two numbers can be considered to match, since they might
represent an input to the procedure. For instance, if the user types "7 X 12.4
+ 9.6 =", the system will record the four-token sequences "7 X 12.4 + ", "X
12.4 + 9.6 " and "12.4 + 9.6 =". If the user later types "106 x 12.4", the
Predictive Calculator will match this sequence with "7 X 12.4 + ", and predict
" + ".
Metamouse analyzes each of the user's drawing actions individually, examining
the state of the drawing before and after. All actions are assumed to have a
goal of moving the mouse cursor (and any object attached to it) so that objects
touch each other in a certain way; for instance, the user might drag a line to
touch both top corners of a box. Metamouse represents the goal as a list of
required touches. It generalizes from a single example, so it picks touches
according to rules, rather than looking for the same touches re-occurring in
multiple examples. The rules rank touches according to precision and causation,
and the system guesses that the highest ranked touches are the intended goal.
On the theory that more precise fittings are less likely to be caused by
chance, it gives more precise touches a higher score. For instance, since a
point-to-point touch has fewer degrees of freedom than a point-to-line touch,
point-to-point touches are ranked higher. The other factor considered is
whether or not the action caused the touch to happen. Touches that were caused
score higher than those which held true anyway. Metamouse also records a
history trace and matches actions when they appear to have the same goal. This
enables it to predict loops or (when actions mismatch) discard a mistakenly
inferred loop. It forms branches (and loop-exits) when it fails to achieve an
action's goal, defaulting to alternative actions demonstrated by the user.
Eager's inference engine determines whether two or more commands fit into a
regular pattern. It first checks that all of the commands have the same verb
(e.g. "Cut Button"). Then, for each argument to the command, it consults the
developer's knowledge base to see what properties of that argument can be used
for a pattern. For instance, the argument to the Cut Button command is a
button, and the HyperCard knowledge base states that the Name, Number or ID of
a button can be used for a pattern. So if the user cuts a button named "A" and
later cuts a button named "B", Eager can match the two Cut Button commands,
because their Names fit into the pattern "A, B, C, ...".
Inferring data descriptions
Data descriptions are abstractions for referring to objects. When a PBD system
is attempting to find an appropriate description for a given object, its
inferencing scheme determines what other objects will be considered for
comparison, and the properties of those objects that will be admissible in
patterns.
Compound descriptors Suppose a user wants to select "all New England
customers with small orders". For a PBD system to infer this concept, it might
need to recognize the data description "all red rectangles that are less than
15 pixels high". One way to characterize capabilities of this sort, which is
common in Machine Learning literature, is to specify whether the inference
engine is able to infer conjuncts of features, or even disjuncts of conjuncts
(see "Disjunctive Normal Form" in the Glossary). In this case, the data
description is a conjunct: "Object with Type = rectangle AND Color = red AND
Height < 15". Selecting "all East Coast customers with small orders"
might entail selecting "all red, orange or brown rectangles that are less than
15 pixels high", which could be described as a disjunct of conjuncts.
Inferring program constructs
Conventional programming languages have special constructs for specifying
loops, conditionals, and arguments to procedures. PBD systems need to have
corresponding techniques to achieve comparable effects.
Iteration Iteration constructs can be classified as set iteration,
iteration with a counter, and iteration until a condition is satisfied.
SmallStar, Peridot and Metamouse support set iteration. Eager can infer set
iterations, iterations with a counter, and some "repeat-until" iterations.
Conditional branches Conditionals allow a program to execute different
code in different situations. They have traditionally been difficult to specify
by demonstration, since it can be laborious to demonstrate each complete path
through a program. Pygmalion, Tinker and Metamouse address this issue by
allowing the user to postpone recording the "else" part of a conditional until
that situation arises during the use of the program.
In Pygmalion, the user must foresee where conditionals will arise and
explicitly specify an if-then-else operator at that point in the demonstration.
Tinker automatically detects the need for a conditional whenever the actions in
a new demonstration differ from the actions in the program, and it then has the
user specify a predicate which will distinguish the new branch. Metamouse
detects the need for a conditional when it fails to satisfy constraints. For
example, suppose Metamouse predicts that the user will drag a line so that its
endpoints touch two opposite corners of a box, but there is no box of the right
size. Metamouse will tell the user that it cannot find a box and ask for a new
action. It then forms a conditional, trying to find a box first, but doing the
new action if that fails.
Arguments When a recorded procedure is invoked in a new context, it must
establish bindings for the various objects in the program. In Peridot, the user
specifies the arguments to a procedure in the same way as in a conventional
programming language. An argument can be specified in Chimera's macros by
example system by selecting an occurrence of the object in any of its graphical
history panels and giving it a name. Arguments are then displayed in separate
panels at the beginning of the macro window. In Mondrian and AIDE, objects
selected prior to the start of a demonstration constitute the arguments to the
demonstration, and the order of their selection is significant.
Multiple examples and negative examples
Some systems, like Chimera's macros by example, make inferences based on a
single example. Others, like Eager and AIDE, generalize across multiple
examples. While negative examples have been very useful in machine learning,
they are problematic for demonstrations. It is difficult to demonstrate, for
instance, that an object was selected because it is not red. TELS and Eager
make use of negative examples in a very limited way: these systems make
predictions, and if the user rejects the prediction, they treat the prediction
as a negative example. Turvy illustrates a broader potential for utilizing
negative examples: it allows unsolicited natural language input to accompany
demonstrations, so the user could state, for instance, that an object is
selected because it is not red.
Felicity Conditions
User demonstrations are a form of instruction for the PBD system, and just as
with instructions to a human student, there are good examples and bad examples.
Good instruction obeys certain "felicity conditions" [van Lehn 83]. These are
criteria -- such as "show all work" -- which ought to be satisfied by a
demonstration if a student is to learn from it effectively. User demonstrations
often violate these conditions, and this poses added difficulties for
inferencing.
Show all work Sometimes a user will not perform an action because the
current example is fortuitously already in the desired state. For instance, a
demonstration of a program which makes text bold and italicized might only
include the "Make Italic" command if the current selection happens to already
be bold. Such a demonstration violates the "show all work" rule, and makes it
difficult for the PBD system to determine that the generated program should
include a "Make Bold" command.
Be consistent Users are sometimes inconsistent in the order in which
they perform the steps of a task, if the order does not affect the performance
of the task. Nonetheless, this inconsistency is an added challenge for an
inferencing system. Also, in cases where there are multiple commands which
achieve the same result, users may use different commands from one
demonstration to the next. Eager is capable of matching different sequences of
navigation commands (i.e. commands for moving from card to card) that achieve
the same effect. It is useful to note that non-trace-based systems, like
Tourmaline, avoid these consistency problems altogether.
Correctness Users sometimes make mistakes during a demonstration. Most
current systems require that the user performs the demonstration perfectly,
although non-trace-based systems are unaffected by mistakes, as long as they
are corrected. Possible remedies include an Undo command as in Chimera,
detecting and removing error-and-fix combinations (see [Lerner 89]), and
allowing the user to later edit errors out of the recorded demonstration, as in
Chimera's graphical histories. Some machine learning algorithms can accept
noisy data, but they generally require a large number of demonstrations as
input.
No extraneous activity Users sometimes perform actions that are not
incorrect, but that do not contribute directly to the goal of the task. For
instance, users may make extraneous selections before making the appropriate
selection and applying a command to it. It may be difficult for an inferencing
system to detect and ignore extraneous commands.
Knowledge
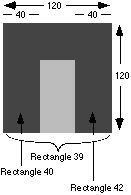
Using knowledge to resolve ambiguity
When an inference engine generalizes, it often produces several interpretations
which are valid and then selects the most appropriate one. The quality of the
interpretations and of the selection is dependent on the knowledge that can be
brought to bear on the inference process. For example, when the user constructs
the final pillar of an arch in Mondrian (see Chapter 16), the system might have
information about the other attributes of the rectangle, the objects it
intersects, and nearby objects. It might know that
- Rect-42 (the final pillar) is 40 pixels wide and 120 pixels high,
- Rect-40 (the first pillar) is "near" and to the left of Rect-42 and is 40
pixels wide and 120 pixels high, and
- Rect-39 (the enclosing square) contains Rect-42 and is 120 pixels wide and
120 pixels high.
Based on this information, an inference engine could
potentially generate a large number of valid descriptions for the width of the
final pillar, such as:
- "40 pixels",
- "1/3 of its height",
- "1/3 of the width of Rect-39",
- "the width of Rect-40",
- "the width of the object created in the command before last", and
- "1/3 of the height of Rect-40".
Heuristics to guide the selection of
the most appropriate inference might include
- * "look for relationships between different parts of the same object",
- "look for relationships between the same parts of different objects",
- "the relationships 1/1, 1/2, 1/4, 1/3 are more important than other
relationships",
- "relationships within an object are more important than relationships
between objects" and
- "the proportional-relationship rule is more important than the
within-object-relationship rule".
These heuristics could be used to
resolve the ambiguity and select the inference "the width of Rect-42 is 1/3 of
its height" as the most likely one.
Types of information
There are several types of information that can help the inference engine
create and select interpretations of the user's actions. And although we will
only consider inferences for program creation and modification (i.e. inferences
about data descriptions and program constructs), it is worth noting that PBD
systems could also use demonstrational techniques to infer invocation.
- Information about user actions The main source of information for
PBD systems is the user's demonstration. Typically, whenever the user performs
an action, a description of that action is recorded in a history list. The
description could be in scripting language or in an internal data
representation.
- Most PBD systems work with high-level information that has semantic
meaning for the application. For example: "Create rectangle Rect-42 with
upper-left: (440,30), lower-right: (480,150)" for a graphical editor; and "Copy
words 2 through 3 of line 1" for a text editor. The Predictive Calculator
receives low-level information: it processes keystrokes rather than arithmetic
commands. So instead of recording "(Add 4 1)", it records "4", "+", and "1".
Triggers is unique in that it uses extremely low-level information -- namely,
the bits on the screen. Tourmaline processes high-level information, but
instead of recording user commands, it examines the final state of the text
that has been formatted.
- Information about object attributes Any single description of a
user action necessarily implies a particular way of interpreting that action.
Since inferencing involves finding alternative interpretations, it is important
for the PBD system to have access to additional information about the
attributes of the action and the objects involved in the action. For instance,
the attribute values of a rectangle could be "width: 40, height: 120, color:
green", and a text selection could have the attribute values "Text: 'Meeting
tomorrow', Font: Helvetica".
- Information about context In addition to information about the
action itself, it can be useful to acquire information about the context in
which the action occurred. Context includes information such as the global
state of the environment (e.g. "Current paint color: red", "Current tool:
eraser"), and information about objects "near" to objects involved in the
action (e.g. "Text before the selection: 'Subject:'", "Objects intersecting the
current object: Rect-39").
- PBD systems differ in the amount and kind of contextual information they
consider when trying to interpret a particular object or event. To find
relationships between objects, a PBD system might compare a parameter of the
current command to the corresponding parameter in an earlier occurrence of that
command, to all objects in the previous command, or to nearby objects in the
current environment. Theoretically, the entire state of the environment before
and after an action could be recorded as relevant context for interpreting the
action, but this is generally not practical. Eager allows the application
developer to specify what context should be used when looking for patterns for
a given object. Chimera uses "Undo" and "Redo" to recreate the application
state that existed when each of the commands was originally demonstrated,
allowing the complete context to be examined during generalization.
- Information about the application domain Information about
typical activities in a given application domain can be very useful for guiding
generalization. For instance, Peridot has a rule to recognize "one rectangle
nested inside another with the same size margin all around except at the top".
This rule would be strange for a generic graphical editing application, but
since Peridot's application domain is the creation of user interfaces, the rule
is quite appropriate: it is common for windows and menus to have extra space at
the top to accommodate a title. In contrast, the Predictive Calculator of
Chapter 3 has almost no domain-specific knowledge about calculator sequences,
and so it will learn meaningless sequences such as "1 1 + + 1 1 + +".
- General world knowledge A large part of the difficulty in inferring
intent comes from the fact that users can interpret text as natural language
and graphics as pictures. World knowledge, such as the fact that "Monday,
Tuesday, ... are days of the week", or that "Jean Miller is the name
of a person", can help systems detect patterns.
- Information about the user Analogous to information about an
application domain, information about a user allows a PBD system to tailor its
interpretations. For instance, a mail system could benefit from knowing that
"this user considers messages from Jean Miller to be high priority", or that
"this user always files messages from Jean Miller in the Miller folder".
While this is the sort of information that current PBD systems produce
-- that is, they could create programs that will flag messages from Jean Miller
as high priority, or that will automatically file a message from Jean Miller in
the Miller folder -- none of the current systems adds this sort of
information to its own knowledge base so that it can be used in later
inferencing.
- Inferencing knowledge All inferencing systems have some sort of
rules which determine how they go about detecting patterns, as well as which
patterns to detect. Most systems also have rules for rating the relative
significance of different patterns. Rules need not be specified declaratively;
they may be implicit in the procedures that implement the inference engine.
- Eager has an extensible declarative knowledge base of datatypes and
pattern-matching predicates for them. For instance, the integer datatype
currently has predicates to detect equality, increments or decrements by 1,
linear patterns, and linear patterns within a fixed error. However, Eager's
ability to detect set iteration is implicit in procedural code. Adding
recognizers for other types of control flow would require modifying the
program.
- Metamouse has heuristics for comparing the significance of different types
of intersections, Chimera has heuristics for rating the likelihood of possible
generalizations of a command, and Mondrian has heuristics for ranking the
significance of relationships between objects. Peridot has declarative rules
specifying possible graphical constraints between objects, when to infer loops
and conditionals, whether an item is a constant or a variable, and how the
interface should respond to the mouse. In Peridot, the rule order is hard-wired
and heuristically determined.
Sources of information
Not only are there numerous types of information, there are also numerous
sources of information: the developer of the PBD system, the developer of the
application program, a domain expert, the end user, and the application
program. The AIDE system provides a framework so that application developers
can specify information about their application, and it provides a search
dialog box so that end users can specify data descriptions.
When information comes from the user, we will be interested in the user
interaction. For instance, Turvy accepts unsolicited advice, Chimera gets
information implicitly from the user's construction lines (used in
snap-dragging), and Peridot uses English queries to ask for confirmation.
Producible programs
A useful measure of the capabilities of a PBD system is the class of programs
that it can generate. One can also specify which program structures are
available in a system. These include variables (local and global), parameters
(required, optional, variable-length, and with default values), return values,
typed objects, operators (Boolean, numeric, and string), conditionals, and
loops. For instance, Pygmalion, Tinker and The Geometer's Sketchpad can
generate recursive programs. Pygmalion, Tinker, Rehearsal World, Peridot,
Chimera, The Geometer's Sketchpad, Mondrian and AIDE can create parameterized
procedures. The summary sheets at the end of each chapter in Section I list the
capabilities and program structures of each system.
Since we are ultimately interested in developing systems which help end users,
any measure of a system's "producible programs" needs to be qualified by an
understanding of whether users are able to effectively demonstrate these
programs, and whether users do in fact want to create programs of this
sort. Hopefully, the Test Suite in Appendix B will grow into a wide-ranging
compendium of real-world tasks that end users want to automate by programming
by demonstration.
Characterizing the Future of PBD
PBD systems have been the stuff of fascinating papers, intriguing videos and
surprising experiments. It is impressive to watch the computer format a
complicated table or organize a stack of mail messages -- without the user
writing a single line of code! But PBD is not quite ready for the wide world of
real users, and it is worth reflecting on why this is so. The two flavors of
PBD -- inferencing and non-inferencing -- have complementary capabilities and
limitations. It is easy for end users to put instructions into inferencing
systems, but they have limited control over the behavior that comes out. Thus,
inferencing systems are branded as unreliable, and their potential to rid the
user of tedium is countered by their potential to do the wrong thing.
Non-inferencing systems, on the other hand, put the burden of generalization on
the user. Instructing these systems requires more knowledge, planning and
effort. The user has more control, but can all too easily get bogged down in
the process of creating programs.
We look forward to seeing practical systems for programming by demonstration in
the near future -- systems which strike a careful balance between ease-of-use
and power, and which succeed in bringing the power of programming to end users.
Summary Sheets
The summary sheets that can be found at the end of each chapter in Section I
are based on the characterization presented in this chapter. Listed on the next
page are all of the categories used in the summary sheet. To conserve space,
individual systems omit headings if they do not have a specific comment about
that area.
System Summary
Uses and Users
Application domain:
Tasks within the domain:
Intended users:
User Interaction
How does the user create, execute and modify programs?
Feedback about capabilities and inferences:
Inference
Inferencing:
Types of examples:
Program constructs:
Knowledge
Types and sources of information:
Implementation
Machine, language, size:
Notable Features
back to ... Table of Contents Watch What I Do